Why we need MapReduce …
越來越的資料被記錄,單個機器已經無法處理和儲存這麼大量的資訊。沒辦法在單一個機器上完成,需要分散式的儲存跟處理。而 MapReduce 是一種分散快速處理資料的方法。
More and more data has been recorded, it’s impossible to store and process data on single machine. Since one machine can not handle such amount of data, the data needs distributed storage and processing. MapReduce is a way to distributed and fast processing large data.
Desired properties of MapReduce …
1.可以擴展 Scalable
在多台機器上面運算,並且可以新增或減少機器。
It can be calculated on several machines and it can simply adding or removing machines.
2.錯誤容忍 Fault-tolerance
若有機器故障,不會影響其他機器處理資料。
If one machine goes down, it won’t affect other machines.
3.可以廣泛使用 Wide applicable
夠簡單,程式人員可以定義或者客製化。
It is simple enough so that programmer can define or customize.
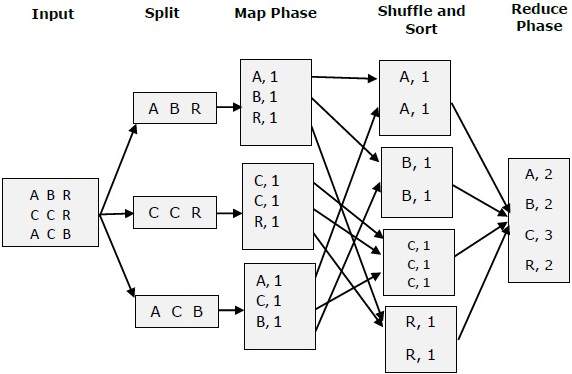
How MapReduce works …
1.Map Operation
根據輸入的關鍵字,計算出相對應的值,產生中介 <Key,Value> 的資料
以上面的圖來看,想要計算出每個字出現的次數。所以 Map operation 根據內容,計算出相對應的值,產生 <A,1>,<B,1>,<R,1>… 等中介資料。
Map operation will calculate value according to key and generate intermediate <key,value> pairs.
In above figure, it want to count every character. Map operation first calculate value of each character and generate <A,1>,<B,1>,<R,1> … intermediate pairs.
2.Reduce Operation
合併相關的中介資料,並且產出最終結果。
上圖而言,Reduce operation 合併相關的中介資料,產生出最後每個字的對應數值。
Merge together the intermediate <key,value> pairs and generate the result.
In above figure, Reduce operation merge the relative intermediate pairs and generate the final result of each character.
Process …
1.
原始的輸入資料被隨機分散成好幾份,分別到不同的機器進行運算。
The raw input data is divided into several pieces and send to different machine to process.
2.
執行 Map Operation 產生出中介值。
Executes Map operation and each machine generates a set of intermediate key value pairs.
3.
將資料依據 Key 值重組排序。
According to key, data will be shuffled and sorted.
4.
執行 Reduce Operation 產生出最終結果。
Executes Reduce operation and generates the results.
-MsHe
