
About synchronization
在分布式系統中,這是一個很大的問題。多台機器之間的資料同步,確保使用者不會讀取到錯誤的資料。我會假設一個情境,下面的解說,將會根據情境講解。希望這樣大家比較好理解。
In distributed systems, synchronization is a difficult problem. How to synchronize between machines and make sure users get the correct data. I will assume a story and explain synchronization according to the story. Hope you can understand better in this way.
The story …
現在,我們有一間銀行。在 A 跟 B 地方各有一台機器。一位客戶原本有 500 元在帳戶中。他到 A 地方去存 10 元,但這時銀行在 B 地方給了他 1% 的利息。所以現在
A 地方 : $510
B 地方 : $505
Now, assume there is a bank. There is a machine in A city and B city each. A customer has $500 in his account. He goes to deposit $10, in the same time bank pays him 1% interests. So now,
A city: $510
B city: $505
If synchronize now …
A 地方: $510 * 1% = $515.1 (給 1% 的利息)
B 地方: $505 + $10 = $515 (存 10 元)
A city: $510 * 1% = $515.1 (pay 1% interests)
B city: $505 + $10 = $515 (deposit $10)
Concept …
同步的核心概念:在所有機器中,所有的更新順序是一致的。
Core concept of synchronization is that apply updates in the same order at all machines.
Replicated State Machine (RSM) …
- 每一台機器都是一個狀態機器 Every replica models as state machine
- 每一台機器有各自的狀態,按照一樣的順序執行更新,確保最後的狀態一致。
- Given identical states, applying updates in the same order in same final state.
- Over time
- 如果有一個機器壞掉了,重啟新的一台。
- Starts a new replica if one goes down.
- Over space
- 可同時執行好幾台機器
- Can run multiple replicas in the same time.
Challenge of RSM
更新順序是按照接收時間,但是每台接收的時間可能不一樣。加上可能會有時間錯誤,或者網路延遲。
Order updates based on the receipts time, but clocks not in synchronous among replicas. In addition, there might be clock drift and time screw, or network latency.
Logical clocks …
1.
捨棄時間,以事件排序。
Disregard precise time, only orders events.
2.
每個事件都有自己的"邏輯時間"。
Every event has its own “logical time".
3.
以邏輯時間,排序所有事件。
Order all events based on “logical time".
Rules of Logical clocks
1.
每個序列初初始時間為 0
The initial logical clock is 0 in each procedure.
2.
每條序列中,若發生事件,則時間加一
In every procedure, logical time add 1 if event happens.
3.
接收到別條序列的訊息,則選擇最大時間 +1
Received message from other procedures, then choose the maximum clock and add 1.
4.
若 C(a) < C(b) ,則代表 a 發生的時間早於 b
If C(a) < C(b) which means a event happened before b event.
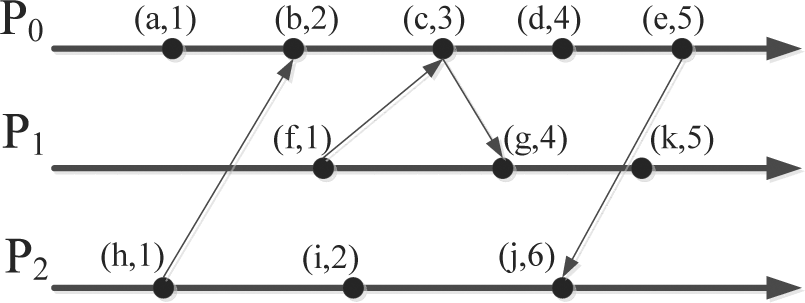
Above figure …
以 P0 為例
1. 發生事件 a, 邏輯時間加一,所以為 (a,1)。
2. 接收到 P2 的訊息,P2訊息時間為1,跟P0 時間一樣,最大值加一(1+1),所以為 (b,2)
3. 接收到 P1 的訊息,P1 訊息時間為1,P0 時間為2,最大值加一(2+1),所以為(c,3)
4.C(a) < C(b),a 事件發生在 b 事件之前
In term of P0
1. Event a happened, logical clock added 1, so it’s (a,1).
2.Received message from P2, the logical clock of P2 is 1 which is the same as P1, so the maximum clock added 1(1+1), it’s (b,2).
3.Received message from P1, and the logical clock of P1 is 1. P0 is 2, so the maximum clock added 1(2+1), it’s (c,3).
4. C(a) < C(b) which means a event happened before b event.

Back to the example …
現在假設
A 地方: 存錢的邏輯時間為 (a,2)
B 地方: 給利息時間為 (b,3)
則 C(a) < C(b),所以兩台機器應先執行 A 事件,在執行 B 事件。
Now assume,
A city: the logical clock of depositing $100 is (a,2)
B city: the logical clock of paying interests is (b,3)
so C(a)<C(b) which means it should update A event before B event.
Waiting time …
如果每次更新前,都要確認事件順序的話,會花很多等待時間。
If it needs to check the order before every update, it would take long time.
There are two ways to solve this problem
1.
定期更新所有的節點,不用等到有更新時,才同步。
Periodically synchronize all nodes.
2.
允許暫時的不一致,但這需要記住狀態,才可以回滾。
Allow temporary inconsistency. It needs to log in order to rollback.
-MsHe

有一則關於 淺談 Synchronization 的留言